![]() Multimodal ArXiv
Multimodal ArXiv
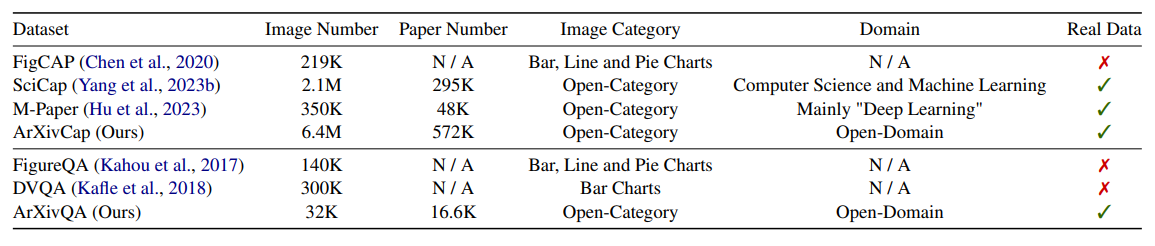
Comparison with previous scientific figure datasets. Our ArXivCap is the largest captioning dataset and our ArXivQA is the only QA dataset that covers a wide range of domains from real papers.
Overview of our dataset curation process. Starting from the ArXiv paper source files, we ensure the paper quality by selecting papers according to publication records. Figure and caption pairs are extracted and then cleaned according to manually designed rules. ArXivQA is generated by prompting GPT-4V with a curated template.

![]() Example
Example
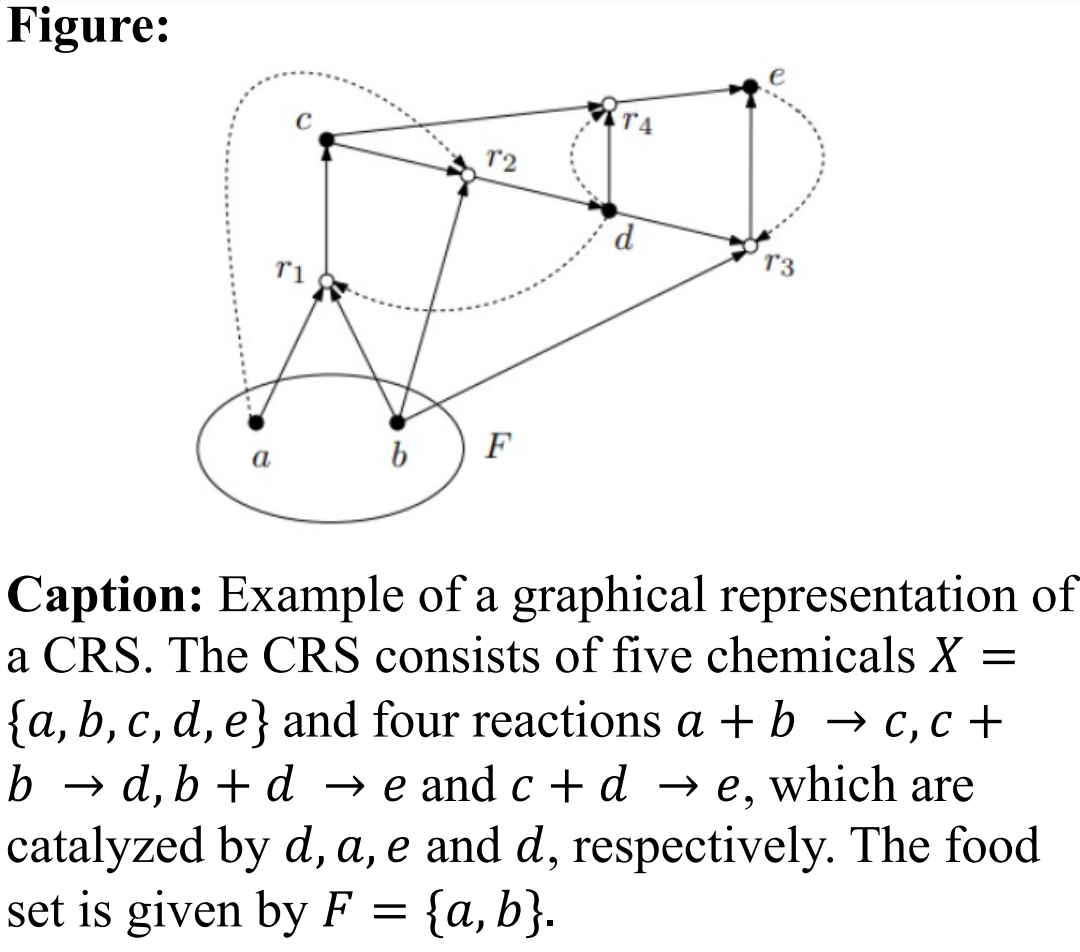
A single-figure caption pair in our ArXivCap dataset. (The figure and caption are from paper arxiv:1908.04642.)
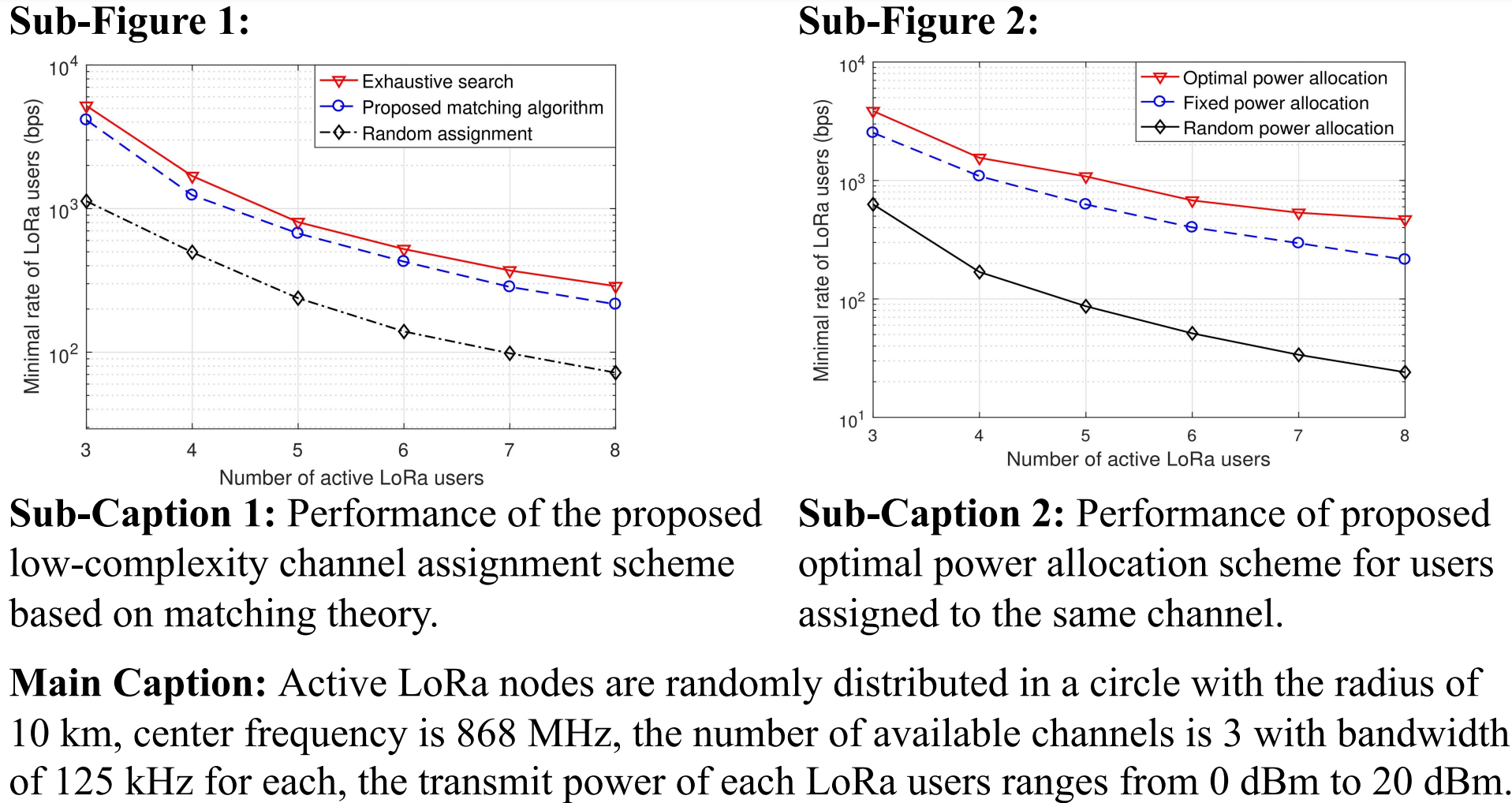
A multiple-figure caption pair in our ArXivCap dataset. (The figure and caption are from paper arxiv:1810.10761.)
A case from ArXivQA. (The figure and caption are from paper arxiv:2011.09217.)

![]() Evaluation
Evaluation
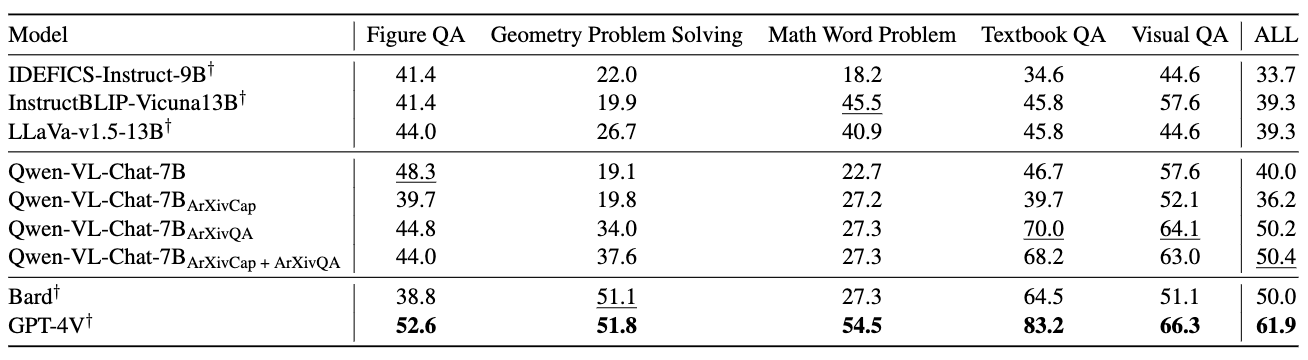
Evaluation on MathVista dataset. ArXivCap and ArXivQA together enhance Qwen-VL-Chat's overall performance, surpassing that of the commercial model Bard. The best results are highlighted in bold, while the second-best scores are marked with underline.
Evaluation results of single figure captioning. Grey results are obtained from a 500-sample subset. Despite most LVLMs struggling to produce high-quality captions of scientific figures, training with ArXivCap significantly boosts the performance.
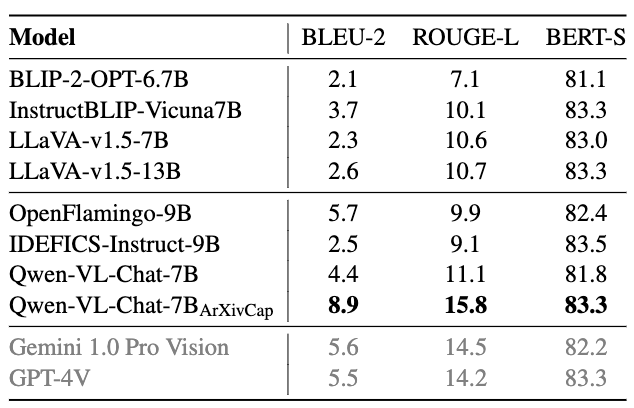
Evaluation results of single figure captioning with paper meta information.
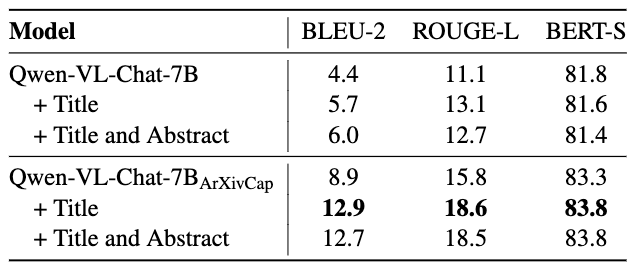
Evaluation results of three newly defined tasks. The best results are highlighted in bold.
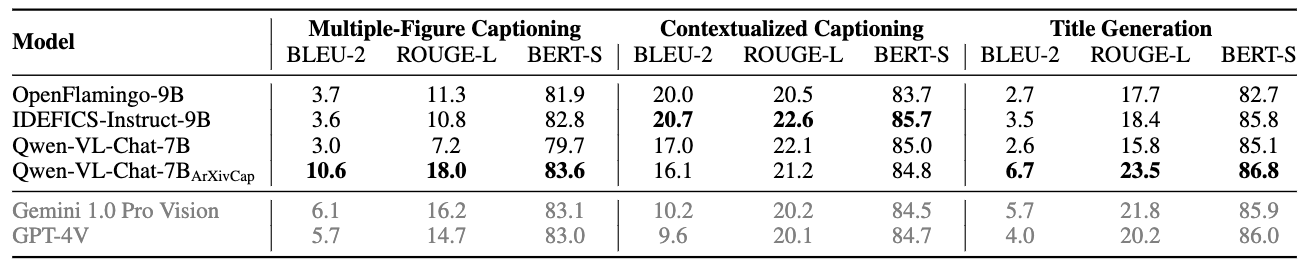
Relative accuracy changes brought by the training on different domain ArXivQA samples.
Manual Evaluation
We conduct a manual inspection for single-figure captioning results. To ensure a more informed evaluation, we focus on a paper from the CS domain, leveraging our domain knowledge to assess caption quality better.

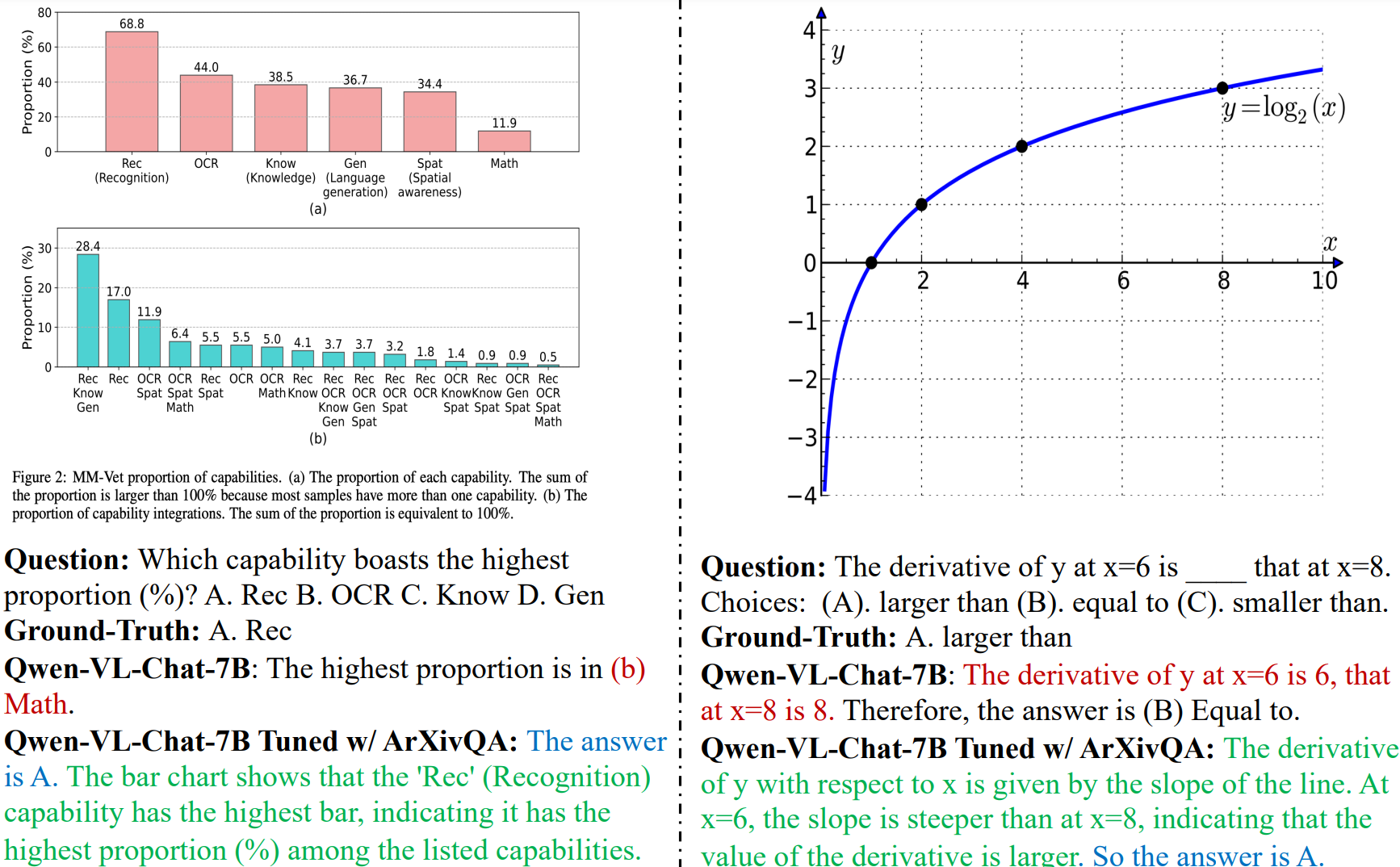
Case Study
ArXivQA enables the model not only to answer questions related to scientific figures in papers (left) but also to improve mathematical understanding ability (right). The model not only selects correct options but also gives reasonable rationale.
BibTeX
@inproceedings{li-etal-2024-multimodal-arxiv,
title = "Multimodal {A}r{X}iv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models",
author = "Li, Lei and
Wang, Yuqi and
Xu, Runxin and
Wang, Peiyi and
Feng, Xiachong and
Kong, Lingpeng and
Liu, Qi",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.acl-long.775",
doi = "10.18653/v1/2024.acl-long.775",
pages = "14369--14387"
}
Acknowledgement
This website is adapted from Nerfies and LLaVA-RLHF, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Usage and License Notices: The data, code and checkpoint is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of Qwen-VL and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.